Abstract
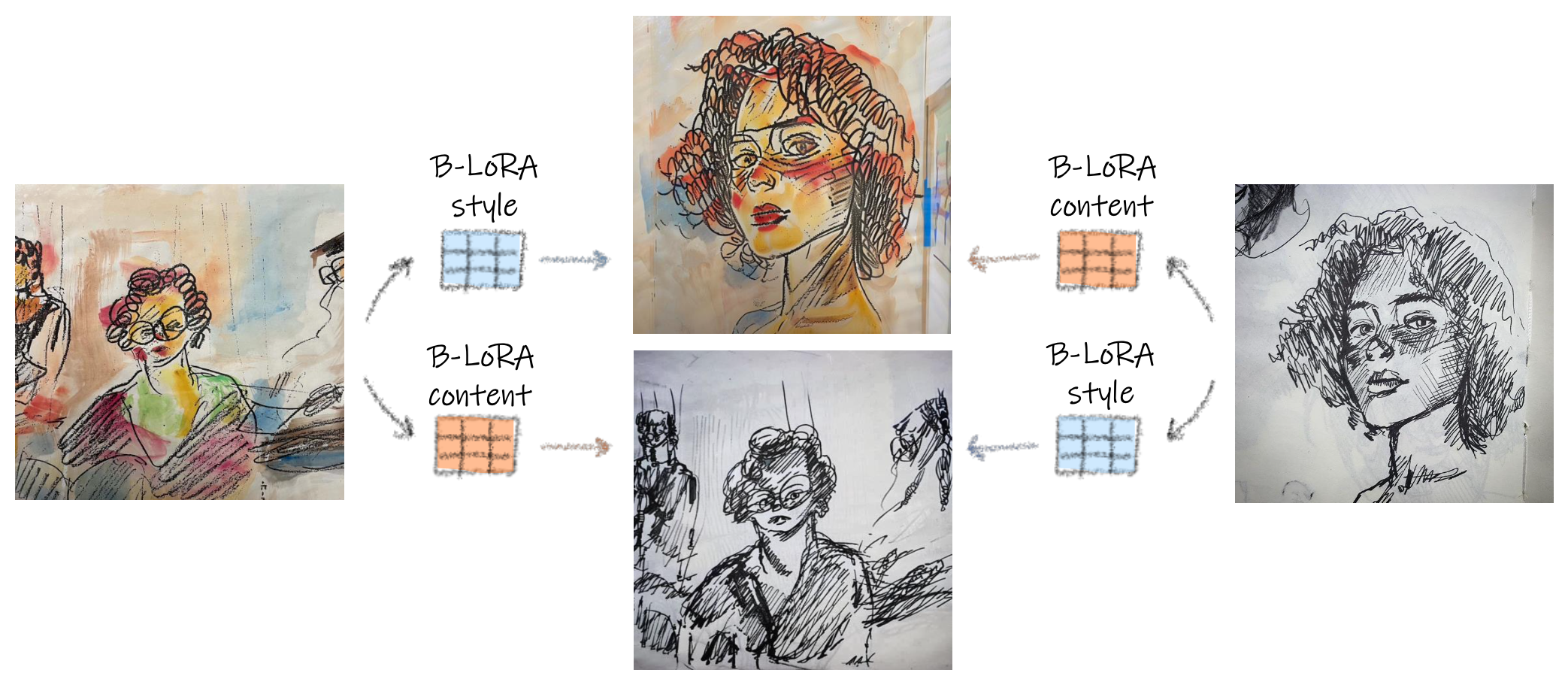
Image stylization involves manipulating the visual appearance and texture (style) of an image while preserving its underlying objects, structures, and concepts (content). The separation of style and content is essential for manipulating the image's style independently from its content, ensuring a harmonious and visually pleasing result. Achieving this separation requires a deep understanding of both the visual and semantic characteristics of images, often necessitating the training of specialized models or employing heavy optimization. In this paper, we introduce B-LoRA, a method that leverages LoRA (Low-Rank Adaptation) to implicitly separate the style and content components of a single image, facilitating various image stylization tasks. By analyzing the architecture of SDXL combined with LoRA, we find that jointly learning the LoRA weights of two specific blocks (referred to as B-LoRAs) achieves style-content separation that cannot be achieved by training each B-LoRA independently. Consolidating the training into only two blocks and separating style and content allows for significantly improving style manipulation and overcoming overfitting issues often associated with model fine-tuning. Once trained, the two B-LoRAs can be used as independent components to allow various image stylization tasks, including image style transfer, text-based image stylization, consistent style generation, and style-content mixing.
Image Stylization Based On Image Style Reference



































Image Stylization Based On Object Image Reference






























Image Stylization Based On Style Image Reference



























Image Stylization Based On Text Reference
Content
"Made of Gold"
"... Wood"
"... Glass"
"... Wool"
"... Steel"


































How does it work?
Our method leverages the powerful Stable Diffusion XL (SDXL) text-to-image diffusion model and the Low-Rank Adaptation (LoRA) technique to implicitly separate the style and content components of a single input image. We first analyze the SDXL architecture and identify two specific transformer blocks (4th and 5th) that play a crucial role in encoding the content and style information, respectively.
Using LoRA, we optimize the weights of these two blocks, termed B-LoRAs, by reconstructing the input image based on a general text prompt like "A [v]".
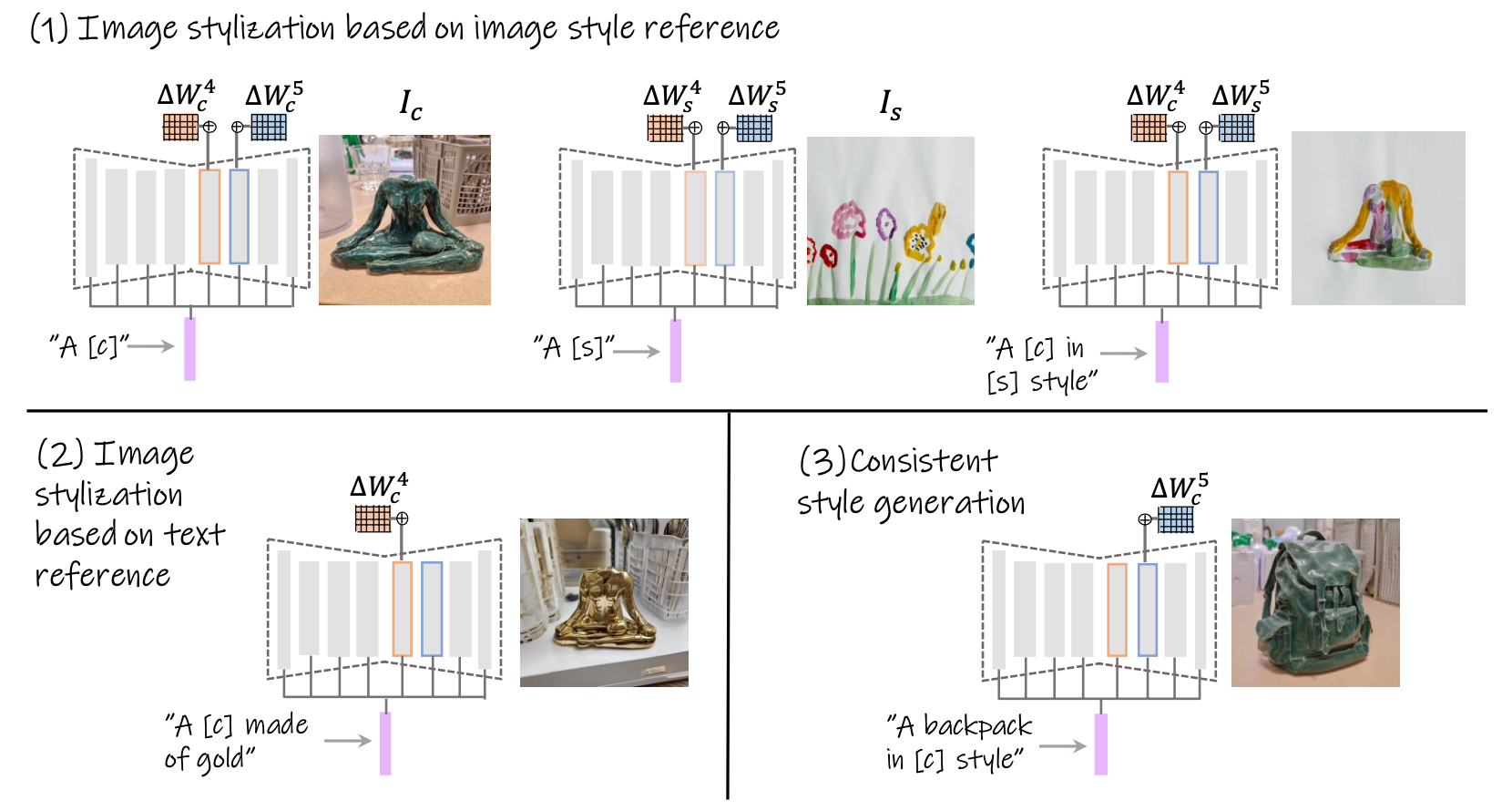
After training, the content B-LoRA \( (\Delta W^4) \) captures the semantic information and structure, while the style B-LoRA \( (\Delta W^5) \) encodes the visual appearance and texture. By combining these B-LoRAs in different ways, the method enables various image stylization tasks, such as image style transfer, text-based image stylization, and consistent style generation, without requiring any additional training or fine-tuning.
Unlike existing methods that require explicit style-content disentanglement or additional optimization, B-LoRA implicitly separates the style and content components of a single input image, enabling various image stylization tasks.
Our approach offers several advantages, including efficiency and flexibility, as it allows for the direct reuse of learned styles and contents without the need for separate models or optimization for each combination.
Additionally, the method demonstrates robustness in handling challenging styles and contents, outperforming alternative approaches that often struggle with overfitting or style leakage issues.
B-LoRA For Personalization
Content
Style
"playing with a ball"
"catching a frisbie"
"wearing a hat"
"with a crown"
"riding a bicycle"
"sleeping"
"in a boat"
"driving a car"






















































Image Stylization from Randomly Selected Content and Style Images with B-LoRA

























































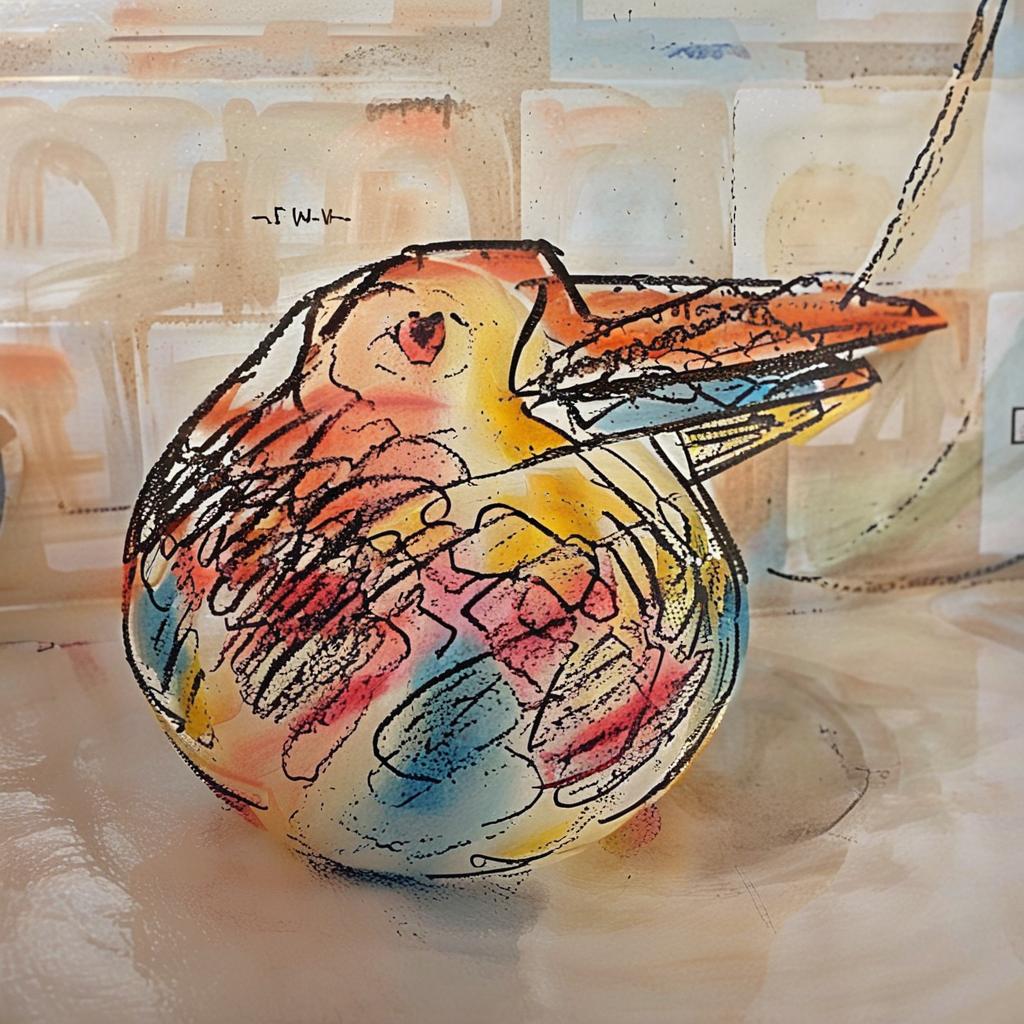









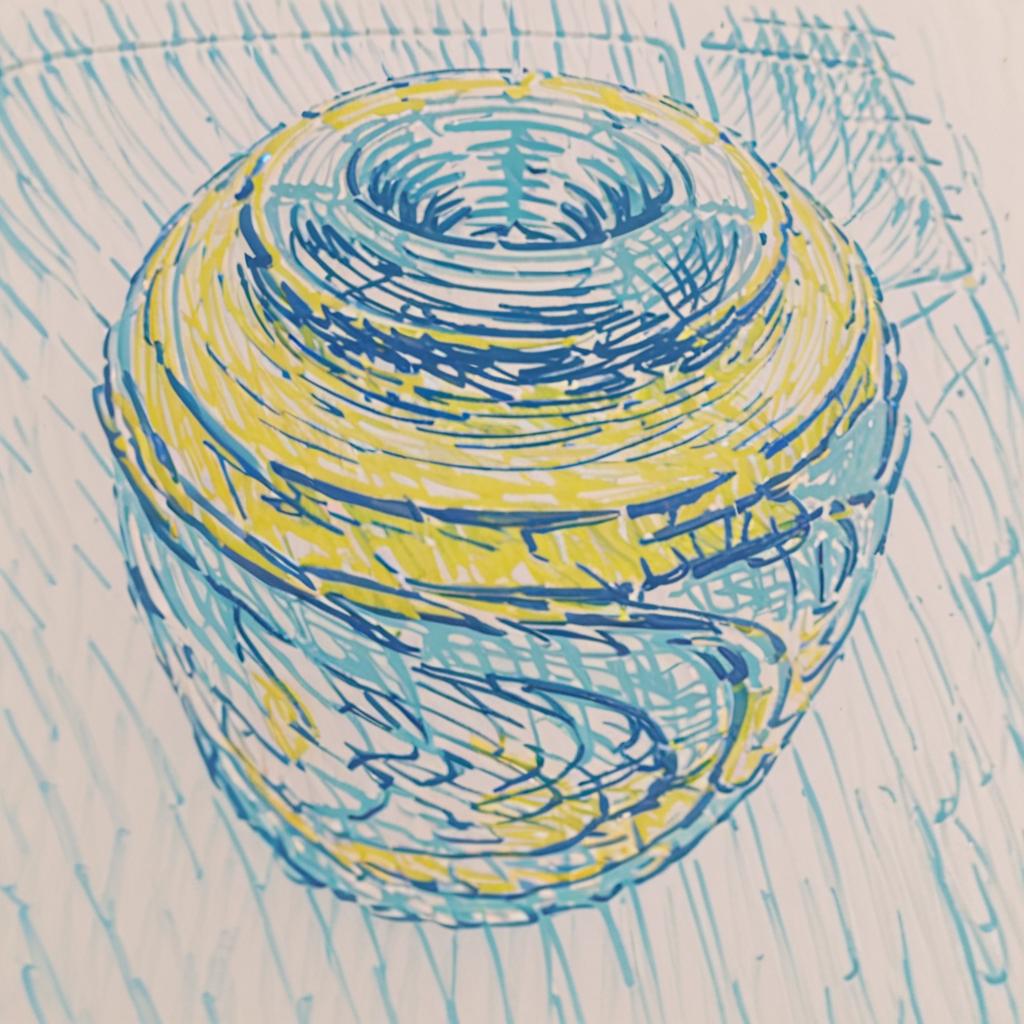





















Acknowledgement
Some of the artistic paintings presented in this paper were created by the artist Judith Kondor Mochary. We thank the artist's family for granting us the privilege to use Judith's drawings.
BibTeX
@misc{frenkel2024implicit,
title={Implicit Style-Content Separation using B-LoRA},
author={Yarden Frenkel and Yael Vinker and Ariel Shamir and Daniel Cohen-Or},
year={2024},
eprint={2403.14572},
archivePrefix={arXiv},
primaryClass={cs.CV}
}